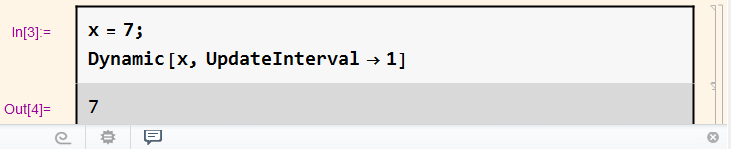
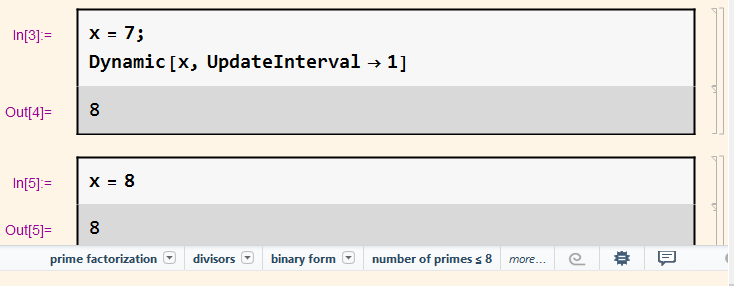
数据写入
测试时生成一百万个随机双精度数,然后写入文件。
1.OpenAppend[]
代码如下:
AbsoluteTiming[file = OpenAppend["data.csv"];
For[i = 1, i <= 1000000, i++,
Write[file, RandomReal[]]];
Close[file]]
用时:21.83s。
2.动态内存分配+Export[]
代码如下:
AbsoluteTiming[temp = {};
For[i = 1, i <= 1000000, i++,
AppendTo[temp, RandomReal[]]];
Export["data1.csv", temp]]
用时:???。程序运行了一个小时都没有结果,所以没有等它运行完成。花这么长时间运行是因为在动态内存分配下,需要大量时间用于分配内存的计算。
3.静态内存分配+Export[]
AbsoluteTiming[temp = ConstantArray[0, 1000000];
For[i = 1, i <= 1000000, i++,
temp[[i]] = RandomReal[]];
Export["data1.csv", temp]]
用时:21.1901s。
4.Map[]+Export[]
AbsoluteTiming[
Export["data1.csv", RandomReal[] & /@ Range[1, 1000000]]]
用时:19.7779s。
5.Map[]+OpenWrite[]
AbsoluteTiming[
file1 = OpenWrite["data2.csv"];
Write[file1, RandomReal[] & /@ Range[1, 1000000]];
Close[file1]]
用时:4.12419s。是的!你没有看错,这种写法仅用于了4.12s,性能是前面的5倍左右!
6.静态内存分配+OpenWrite[]
AbsoluteTiming[temp = ConstantArray[0, 1000000];
file2 = OpenWrite["data3.csv"]; For[i = 1, i <= 1000000, i++,
temp[[i]] = RandomReal[]];
Write[file2, temp];
Close[file2]]
用时:5.68126s。
7.DumpSave[]
AbsoluteTiming[ss = RandomReal[] & /@ Range[1, 1000000];
DumpSave["datama.mx", ss]]
用时:0.0841409s。这个已经快得不像话了.比4.12秒性能提升了几百倍.
8.SQL数据库
AbsoluteTiming[
s = SQLServerLaunch[{"myDb1" ->
FileNameJoin[{$TemporaryDirectory, "HSQLServer"}]}];
conn = OpenSQLConnection[JDBC["HSQL(Server)", "localhost/myDb1"]];
SQLCreateTable[conn, SQLTable["test"],
SQLColumn["col", "DataTypeName" -> "Double"]];
For[i = 1, i <= 1000000, i++,
SQLInsert[conn, "data", "col1", RandomReal[]]];
SQLCommitTransaction[conn];
CloseSQLConnection[conn];
SQLServerShutdown[s]]
用时:7.28357s
从以上的对比中,可以看出,DumpSave[]加函数式编程是最快的一种写入数据的方式。仅需要0.08s就可以生成并写入100万个双精度随机数。其次的为Write[]、数据库方式。